2017下半年参加了CCF BDCI(大数据与计算智能大赛),主要做了其中“让AI当法官”赛题。比赛持续了大约3个月,我们队伍“方唐镜”最终取得了“让AI当法官”赛题一等奖(1/415),CCF BDCI综合特等奖(1/6675)。这是第一次参加自然语言处理和文本相关的比赛,收获很大,希望将来投身到NLP的工作中。接下来是我们用到的方法的总结和分享。
比赛任务
希望通过机器阅读大量的案件事实,自动给出该案件中犯罪嫌疑人所处罚金的范围,适用条款,以提高审判效率,对案件审判的质量进行评价。因此,本赛题的任务分为两个子任务,即对给定的法律案件描述,分别预测出案件的罚金额度范围和对应的相关法律条文。
其中一条数据如下,罚金范围类别为1,对应法律条文为347,25,27,67。
公诉机关无锡市北塘区人民检察院。被告人金某,未办理居民身份证,无业。2013年4月7日因吸毒被行政拘留十日;2013年9月16日因吸毒被查获,次日因吸毒被行政拘留十五日,同年10月2日因涉嫌贩卖毒品罪被刑事拘留,同年11月6日被逮捕。现羁押于无锡市第一看守所。无锡市北塘区人民检察院以北检诉刑诉(2014)45号起诉书指控被告人金某犯贩卖毒品罪,于2014年1月15日向本院提起公诉。经无锡市中级人民法院指定管辖,本院于同年2月25日立案,依法适用简易程序,实行独任审判,公开开庭审理了本案。无锡市北塘区人民检察院指派检察员陈熠出庭支持公诉,被告人金某到庭参加诉讼。现已审理终结。1.2013年9月10日左右的一天,林某某(另案处理)电话联系周某后指使被告人金某出面交易,在无锡市锡山区锡北镇社区卫生服务中心门口将毒品海洛因0.3克贩卖给周某,得赃款300元。2.2013年9月14日左右的一天,林某某电话联系周某后指使被告人金某出面交易,在上述地点将毒品海洛因0.2克贩卖给周某,得赃款200元。2013年9月16日,被告人金某因吸毒被查获,其罪行尚未被发觉,仅因形迹可疑,被公安机关盘问、教育后,主动交代了自己的罪行。 1 347,25,27,67
两类任务分别进行单独评测。对于罚金类别预测,使用Micro-Averaged F1指标衡量模型性能:
$$
micro_avg_F1=\frac{1}{N}\sum_{i=1}^{m}w_i f1_i
$$
其中, m表示类别数目,N表示样例总数,wi表示测试样例中属于第i类的个数,f1i是第i类中的F1值。
对于法律条纹预测,使用Jaccard相似系数:
$$
p_i = \frac{|L^i\cap L_g^i|}{|L^i\cup L_g^i|} \
p=\frac{1}{N}\sum_{i=1}^{N}p_i
$$
其中,Li是标准答案的条文集合,Lig是预测的条文集合。最终得分为0.5*micro_avg_F1+0.5*p。
数据
数据分析
准确预测罚金具有较高的难度,通过查阅相关资料可知罚金与犯罪性质、非法所得数额、嫌疑人经济状况、地区经济发展水平等多种因素相关,并且法官有较大的自由裁量权。预测法条相对简单,特别是涉及到罪名的条款,因为大部分判决书已经明确给出的罪名,其对应条款也比较单一。训练集规模,初赛有4w,复赛有12w。
下图是训练集中法条的分布情况。

数据预处理
主要进行了分词、过滤、划分验证集、数据截断,词向量训练。
首先清洗了一些乱码,过滤了过长过短的文档,分词采用了结巴分词。在训练词向量之前,一个重要的预处理就是把文中出现的金额替换为对应的罚金类别LV1~LV8, 否则在词向量训练过程中数字是学不到东西的,不同的数字被embedding到不同的向量,增加了对金额数字学习的难度,而这些金额数字又是非常重要的特征。这个预处理,使得各个模型的预测性能均有提升。我们的词向量的训练使用的是word2vec, 具体是通过gensim进行的,采用的模型是skip-gram,词频下限是3。
训练集验证集划分比例10:1。
由于数据集中不同样本的长度不一,平均长度800词左右。对于接下来的CNN模型,我们采用了一种特殊的截断方法,如果长度大于2000,则取开始的500词和结尾的1500词。 这样做的原因是,数据集中典型的犯罪名称在头尾出现的较多,这样比直接截取前2000词模型得分提高0.6%左右。
对于法律条文,发现并不是搜索的条文都出现过,所以我们去掉了一些未出现的条文类别,并进行了重新编码。
算法模型
对于罚金类别预测,我们将其看作典型的文本多分类任务,可直接用模型多分类输出;对于法律条文预测,我们采用多二值分类的方法。在总体思路方向上,我们希望各个模型侧重不同的方面,eg:关键词,整体特征,结构化信息等。
我们一共进行了三个思路的尝试。第一,基于搜索的方法,主要是通过人工选择关键词,找出罚金,罪名等,和法律条文中的罪名进行匹配。第二,利用传统机器学习的方法。先通过TF-IDF或N-gram提取特征,再用SVM,Naive Bayes等方法进行分类。第三类,是通过深度学习的方法。我们采用了TextCNN,RNN,Structured模型。最终,通过效果对比,我们只采用了深度学习的三个模型进行融合作为最后的结果。
TextCNN
模型来自论文《Convolutional Neural Networks for Sentence Classification》, 侧重于提取案件中的关键词/短语,例如罪名、地名、罚金等。它的基本思想是用不同大小的卷积核去捕捉不同的n-gram特征,并利用max-pooling提取位置无关信息,最后通过全连接层softmax or sigmoid作分类决策。论文详情可以看我的论文笔记。

参数方面,对于罚金任务,embedding层200维,kernel_size={3,4,5}三种,每个卷积核的输出是500维。max-pooling之后,两层FC,分别750和8维,然后softmax分别。dropout=0.1。对于法条预测,是在max-pooling之后直接一个321的FC+sigmoid作为输出。
训练时,每个epoch验证集上验证4次,两次不上升,lr减半。如果继续两次验证不上升,停止训练。
RNN
该模型用于提取文档上下文与全局语义特征。传统的RNN模型只用最后一个单元的输出作为语义向量,但是这对文本分类来说会丢失很多中间信息,因此我们采用了一种利用全局信息的RNN模型。

RNN单元我们使用GRU,并对这些时间步上的输出进行一个FC(各个时间步共享这个FC的权重), 每一个时间步的结果一起组成了一个Feature Map。然后进行max-pooling来对feature map进行最大池化,然后添加两个全FC,最后进行softmax or sigmoid进行预测。
参数方面,embedding层256维,GRU输出400维,之后的FC也是400维,pooling之后的FC也是400维,最后一层如果是预测罚金就是8,如果是法条预测是321维。
Structured
该模型来自论文《Learning Structured Text Representations》, 在Yelp数据集上取得了准确度68.6的成绩。在预处理时,按照“。?!”分割成句子,每个文本截断前100个句子。每个句子截断前100个词。同时过滤掉空白文本。该模型能够捕获到上述两个模型在原始数据层丢失的语义信息,但作为交换的是训练时间较长(约13小时)。源码地址:GitHub Link。
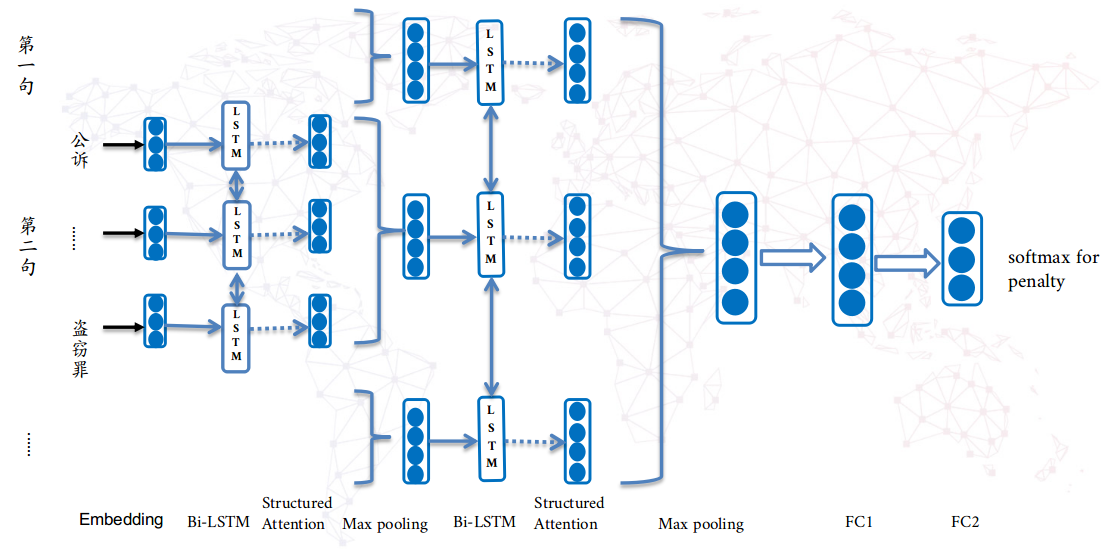
该模型通过句子中词向量,先得到句子的向量表示;再通过文档中句子的向量表示,得到文档的向量表示;最终用该向量表示来做罚金类别预测。对于句子T=[u0,u1,…, un],其中ui是句子中第i个词的向量表示,输入到双向LSTM网络中,对于每个的输出hi向量分成两部分ei和di,即hi=[ei, di],这两部分分别用来表示语义信息和结构注意力信息。然后通过结构注意力机制,获得每个词的新的向量表示[r0, r1,…, rn]。然后进行max-pooling获得句子的表示。在获得document表示的时候,过程类似。文本向量后添加两个全连接层,最终做softmax,就可以得到对于8个罚金类别的预测概率。在具体实现上,我们采用的是max-pooling,全连接层dropout=0.3。
该模型的核心亮点,就是所采用的Structured Attention机制。因为根据Rhetorical Structure Theory ,词之间或者句子之间是存在一种树形依赖的。具体是把LSTM的输出ht=[et, dt],中dt用来做结构信息,来构造邻接矩阵和Laplacian矩阵。然后分别计算每个输出作为根节点的概率,作为其他节点孩子的概率,作为其他节点父亲的概率,通过这些概率得到对其他节点的依赖,再结合自己的语义信息et,拼接得到最终的语义向量。
模型融合
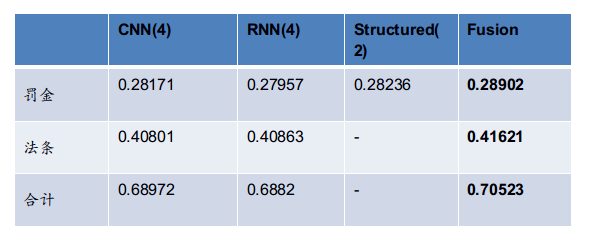
图中是各个模型在已知分数下的预估得分。最终得分70%+,也是本场唯一一个分数过70的队伍。
关于模型融合,最优提交的结果是对概率简单平均之后进行融合的。TextCNN,RNN分别跑了四次,Structured跑了2次,先是每个模型内进行概率平均,减少模型的不稳定。在模型间也是进行简单的平均,对于罚金预测,直接输出最大概率的类别;对于法条预测,输出概率大于0.5的所有条文。
我们也尝试了,对不同模型分配不同的权重,而不是简单的平均。我们划分了训练集/验证集/测试集,使用简单的LR模型,学习不同的权重,发现对于每个法条给每个模型不同权重,一直过拟合。对于不同模型,分配权重,线下是有提升的。然而,线上结果没有提升。
其他
比赛后期是很疲累的,但是收获挺大的。至今还记得复赛封榜时,我们还是第一的时候激动的心情。非常感谢队友,没有队友就不会有这篇文章了。
关于收获,总结起来就是:
- 对于数据的分析和理解、有效的预处理方式非常重要。
- 模型要多样性,最好能互相弥补、互有侧重。
- 认真学习、脚踏实地。